
kaggle加州房价预测心得
先把网址贴出来 加州房价预测
我训练使用的是mlp,最后的结果大概就是0.27左右了,我不知道还能不能继续优化

数据输入与处理
数据读取与观察
我的做法是直接从官网把数据下载到本地再读取的
train_data = pd.read_csv(train_path)
test_data = pd.read_csv(test_path)
train_data.info()
test_data.info() 先读进来看看数据长什么样
| # | Column | Non-Null Count | Dtype |
|---|---|---|---|
| 0 | Id | 47439 non-null | int64 |
| 1 | Address | 47439 non-null | object |
| 2 | Sold Price | 47439 non-null | float64 |
| 3 | Summary | 47085 non-null | object |
| 4 | Type | 47439 non-null | object |
| 5 | Year built | 46394 non-null | float64 |
| 6 | Heating | 40587 non-null | object |
| 7 | Cooling | 26745 non-null | object |
| 8 | Parking | 46065 non-null | object |
| 9 | Lot | 33258 non-null | float64 |
| 10 | Bedrooms | 44567 non-null | object |
| 11 | Bathrooms | 43974 non-null | float64 |
| 12 | Full bathrooms | 39574 non-null | float64 |
| 13 | Total interior livable area | 44913 non-null | float64 |
| 14 | Total spaces | 46523 non-null | float64 |
| 15 | Garage spaces | 46522 non-null | float64 |
| 16 | Region | 47437 non-null | object |
| 17 | Elementary School | 42697 non-null | object |
| 18 | Elementary School Score | 42543 non-null | float64 |
| 19 | Elementary School Distance | 42697 non-null | float64 |
| 20 | Middle School | 30735 non-null | object |
| 21 | Middle School Score | 30734 non-null | float64 |
| 22 | Middle School Distance | 30735 non-null | float64 |
| 23 | High School | 42439 non-null | object |
| 24 | High School Score | 42220 non-null | float64 |
| 25 | High School Distance | 42438 non-null | float64 |
| 26 | Flooring | 35870 non-null | object |
| 27 | Heating features | 39746 non-null | object |
| 28 | Cooling features | 25216 non-null | object |
| 29 | Appliances included | 33846 non-null | object |
| 30 | Laundry features | 32828 non-null | object |
| 31 | Parking features | 42664 non-null | object |
| 32 | Tax assessed value | 43787 non-null | float64 |
| 33 | Annual tax amount | 43129 non-null | float64 |
| 34 | Listed On | 47439 non-null | object |
| 35 | Listed Price | 47439 non-null | float64 |
| 36 | Last Sold On | 29673 non-null | object |
| 37 | Last Sold Price | 29673 non-null | float64 |
| 38 | City | 47439 non-null | object |
| 39 | Zip | 47439 non-null | int64 |
| 40 | State | 47439 non-null | object |
dtypes: float64(18), int64(2), object(21)
这是训练集的信息,
可以看到,序号2的Sold Price就是我们需要预测的值,同时,很多数据有缺失,Cooling列甚至缺失了大约一半的数据。测试集就相比训练集少了Sold Price这一列
数字的数据有22列,离散的object数据有21列,数字很好处理,其实难点就是如何处理离散值。我们当然可以直接把不好处理的丢掉,但是这个显然会丢失很多信息,所以我们要想个办法把它们利用起来
我最初想到的是用独热编码来处理,然后维度就理所当然的爆炸了。几万条数据,特征非常多也是正常的,尤其是summary这种,每个房子都不一样,如果直接粗暴地进行独热编码会导致特征激增,而且这些特征根本提供不了有效信息
我们来进一步看一下信息
| Id | Address | Sold Price | Summary | Type | Year built | Heating | Cooling | Parking | Lot | Bedrooms | Bathrooms | Full bathrooms | Total interior livable area | Total spaces | Garage spaces | Region | Elementary School | Elementary School Score | Elementary School Distance | Middle School | Middle School Score | Middle School Distance | High School | High School Score | High School Distance | Flooring | Heating features | Cooling features | Appliances included | Laundry features | Parking features | Tax assessed value | Annual tax amount | Listed On | Listed Price | Last Sold On | Last Sold Price | City | Zip | State |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 540 Pine Ln | 3,825,000 | 540 Pine Ln, Los Altos, CA 94022 is a single family home that contains 1 sq ft and was built in 1969. It contains 0 bedroom and 0 bathroom. This home last sold for $3,825,000 in January 2020. The Zestimate for this house is $4,111,840. The Rent Zestimate for this home is $8,669/mo. | SingleFamily | 1969.0 | Heating - 2+ Zones, Central Forced Air - Gas | Multi-Zone, Central AC, Whole House / Attic Fan | Garage, Garage - Attached, Covered | 1.0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | Los Altos | Santa Rita Elementary School | 7.0 | 0.4 | NaN | NaN | NaN | Los Altos High School | 8.0 | 1.3 | Tile, Hardwood, Carpet | Forced air, Gas | Central | Dishwasher, Dryer, Garbage disposal, Microwave, Refrigerator, Washer | Washer / Dryer, Inside, In Utility Room | Garage, Garage - Attached, Covered | 886,486.0 | 12,580.0 | 2019-10-24 | 4,198,000.0 | NaN | NaN | Los Altos | 94022 | CA |
| 1 | 1727 W 67th St | 505,000 | HURRY, HURRY.......Great house 3 bed and 2 baths, detached 2 car garage with plenty of parking in the back, interior remodeled, brand new kitchen, flooring, paint, appliances, mini split wall A/C Heater unit, new water heater and new windows, etc....Please come see it to appreciate it. | SingleFamily | 1926.0 | Combination | Wall/Window Unit(s), Evaporative Cooling, See Remarks | Detached Carport, Garage | 4047.0 | 3 | 2.0 | 2.0 | 872.0 | 1.0 | 1.0 | Los Angeles | Raymond Avenue Elementary School | 3.0 | 0.8 | John Muir Middle School | 2.0 | 1.1 | Augustus F. Hawkins High A Critical Design And Gaming | 2.0 | 1.3 | NaN | Combination | Wall/Window Unit(s), Evaporative Cooling, See Remarks | NaN | Inside | Detached Carport, Garage | 505,000.0 | 6,253.0 | 2019-10-16 | 525,000.0 | 2019-08-30 | 328,000.0 | Los Angeles | 90047 | CA |
| 2 | 28093 Pine Ave | 140,000 | 'THE PERFECT CABIN TO FLIP! Strawberry delight in old Strawberry just about a 3-minute walk to the river (you can hear the river from the front deck) is this wonderful 2 bedroom 1 full bathroom and 2 half bathrooms mountain getaway. Built by the current owners in 1958 to last, a metal roof, large front deck, level lot, master bedroom on the main level of the cabin with the full bathroom and 1 half bathroom... [truncated for space] | SingleFamily | 1958.0 | Forced air | NaN | 0 spaces | 9147.0 | 2 | 3.0 | 1.0 | 1152.0 | 0.0 | 0.0 | Strawberry | NaN | NaN | NaN | NaN | NaN | NaN | Long Barn High School | NaN | 10.1 | NaN | Forced air | NaN | NaN | NaN | NaN | 49,627.0 | 468.0 | 2019-08-25 | 180,000.0 | NaN | NaN | Strawberry | 95375 | CA |
我们一列一列地观察,数字类的就略过
- Address是用空格将信息隔开的,我们是否能够将里面的数据用空格分开,归类之后再做独热编码?
- Summary的信息很多,但是我目前没有很好的办法把它提取出来,是否考虑直接丢弃?或者用逗号提取一些信息?
- Type下貌似只有一个单词,应该可以直接用独热编码处理
- Heating下面是组合的特征,一个房子会有很多种供暖的方式,很明显是一个逗号一种,可以考虑通过逗号分开
- Cooling,Parking,以及后面带逗号的都可以这样处理
- Region中虽然有空格,但很明显把它拆开来没有意义
- School那几列似乎不太好处理,但是如果拿空格拆开的话应该也能提取一些信息
- Listed on和Last Sold on这类日期的特征,是不是可以把年月日拆开来处理?
有了这些想法之后,就要想办法写程序处理了
特征工程
先贴代码
def load_data(train_path, test_path, device):
train_data = pd.read_csv(train_path)
test_data = pd.read_csv(test_path)
# train_data.info()
# test_data.info()
#price存起来
train_label = train_data.iloc[:,2]
#丢弃price
train_data = train_data.drop(train_data.columns[2], axis=1)
num_train = train_data.shape[0]
#训练集和测试集放到一起处理
data = pd.concat([train_data, test_data],ignore_index=True)
data = preprocess_data(data)
#再拆开
train_data = data.iloc[:num_train,:]
test_data = data.iloc[num_train:,:]
#转换成tensor
train_data = torch.tensor(train_data.to_numpy(), dtype=torch.float32).to(device)
train_label = torch.tensor(train_label.to_numpy(),dtype=torch.float32).to(device)
test_data = torch.tensor(test_data.to_numpy(), dtype=torch.float32).to(device)
train_label = train_label.view(-1,1)
train_dataset = TensorDataset(train_data,train_label)
blank_label = torch.zeros(test_data.shape[0],1)
test_dataset = TensorDataset(test_data,blank_label)
return train_dataset, test_dataset
def extract_top(features,data,sep,top_n=30):
for feature in features:
exploded = (
data[['Id', feature]]
.assign(**{feature: data[feature].str.split(sep)}) # 按sep分割
.explode(feature)
)
exploded[feature] = exploded[feature].str.strip() # 去除首尾空格
value_counts = exploded[feature].value_counts()
top_values = value_counts.head(top_n).index.tolist()
exploded[feature] = exploded[feature].apply(
lambda x: x if x in top_values else '0'
)
dummies = pd.get_dummies(exploded[feature], prefix=feature)
dummies['Id'] = exploded['Id']
dummies = dummies.groupby('Id',as_index=False).max()
dummies = dummies.drop('Id',axis=1)
data = data.drop(feature,axis=1)
data = pd.concat([data,dummies],axis=1)
return data
def precess_date(data, features):
for feature in features:
dates = pd.to_datetime(data[feature], errors='coerce')
data[f"{feature}_year"] = dates.dt.year.fillna(0).astype(int)
data[f"{feature}_month"] = dates.dt.month.fillna(0).astype(int)
data[f"{feature}_day"] = dates.dt.day.fillna(0).astype(int)
data = data.drop(feature, axis=1)
return data
def preprocess_data(data):
# 处理日期特征
date_features = ['Last Sold On','Listed On']
#data = data.drop(date_features, axis=1)
precess_date(data, date_features)
# 处理数值特征
numeric_features = data.select_dtypes(exclude=['object']).columns
numeric_features = numeric_features.drop('Id')
if len(numeric_features) > 0:
data[numeric_features] = data[numeric_features].apply(lambda x: (x-x.mean())/x.std())
data[numeric_features] = data[numeric_features].fillna(0)
# 处理分类特征
# data = data.drop('Summary', axis=1)
feature_listblank = ['Address']
data = extract_top(feature_listblank,data,' ')
feature_list = ['Summary','Heating', 'Cooling', 'Parking', 'Bedrooms', 'Flooring', 'Heating features','Cooling features','Appliances included','Laundry features','Parking features']
data = extract_top(feature_list,data,',')
categorical_features = data.select_dtypes(include=['object']).columns
if len(categorical_features) > 0:
# data[categorical_features] = pd.Categorical(data[categorical_features]).codes
# data = data.drop(categorical_features, axis=1)
data = extract_top(categorical_features,data,'',top_n=20)
data = data.fillna(0)
bool_features = data.select_dtypes(include=['bool']).columns
if len(bool_features) > 0:
data[bool_features] = data[bool_features].astype(int)
data = data.drop('Id', axis=1)
data = data.select_dtypes(include=['float64', 'int64'])
print(data.shape)
# print(data.dtypes)
# non_numeric_cols = data.select_dtypes(exclude=['float64', 'int64','bool']).columns
# print(non_numeric_cols)
return data- 对于日期特征的处理,思路是把年月日作为整数提取出来,分成三列,然后接到原数据的后面
- 然后再处理数字特征,我们需要把数字归一化(有点像物理上统一量纲的感觉)
- 最后处理分类的特征,使用独热编码,并且为了防止维度爆炸,只提取出现频率top_n的几个特征
日期特征没什么好说的,pandas库的功能很强大
数字特征处理
主要代码是这几句
numeric_features = data.select_dtypes(exclude=['object']).columns
numeric_features = numeric_features.drop('Id')
if len(numeric_features) > 0:
data[numeric_features] = data[numeric_features].apply(lambda x: (x-x.mean())/x.std())#标准化
data[numeric_features] = data[numeric_features].fillna(0)标准化
通过把数据减去均值并且除以标准差,我们把数据标准化为均值为0,标准差为1的的形式,这个做法是为了让模型公平地学习每个特征。
标准化的原理是什么?
某种程度上跟我们这次使用的损失函数有关联
我们就假设我们的网络是一个单层线性模型
$$
\hat{y} = wx^T
$$
$$
l=\frac{1}{2}(\hat{y}-y)^2
$$
把它对某个$w_t$求偏导
$$
\frac{\partial{l}}{\partial{w_t}}=(\hat{y}-y)x_t
$$
可以发现不同权重的导数与特征值有关,如果特征值不均衡,梯度的更新会极度偏向特征值较大的那一方,很容易造成损失的震荡。
你可以想象loss的等高线变成一个椭圆形状的(因为特征值没有标准化),梯度总是沿着椭圆的长轴更新,而且由于梯度还与$\hat{y}$有关,就会让梯度变的不稳定,更新的时候就容易错过最小值的地方(因为图像扁平),模型容易走一个“之”字型更新,导致损失的震荡。如果标准化之后就会变成一个圆,更不容易错过最小值,训练也更稳定。
如果你的损失函数里面含有正则项的话,不标准化的影响会更大。
我们以权重衰减为例
$$
l=\frac{1}{2}(\hat{y}-y)^2+\frac{\lambda}{2}||w||^2
$$
导数是
$$
\frac{\partial{l}}{\partial{w_t}}=(\hat{y}-y)x_t-\lambda||w_t||
$$
问题会更大。因为可以想象,为了模型为了平衡各个特征值的权重,大特征值的权重会偏小,导致这一项几乎不受权重衰减的惩罚。
最后处理缺失值,全部赋为均值0就行
分类特征处理
我的代码里面实现这个功能的是这个函数
def extract_top(features,data,sep,top_n=30):
for feature in features:
exploded = (
data[['Id', feature]]
.assign(**{feature: data[feature].str.split(sep)}) # 按sep分割
.explode(feature) # 展开
)
exploded[feature] = exploded[feature].str.strip() # 去除首尾空格
value_counts = exploded[feature].value_counts() # 统计频率
top_values = value_counts.head(top_n).index.tolist() # 选择前n个
exploded[feature] = exploded[feature].apply(
lambda x: x if x in top_values else '0'
) # 过滤,如果不是前n个的特征赋0
dummies = pd.get_dummies(exploded[feature], prefix=feature) # 独热编码
dummies['Id'] = exploded['Id']
dummies = dummies.groupby('Id',as_index=False).max() # 聚合
dummies = dummies.drop('Id',axis=1)
data = data.drop(feature,axis=1)
data = pd.concat([data,dummies],axis=1)
return data主要思路就是按符号分割,然后展开统计出现频率,独热编码,最后聚合在一起。缺失值我赋了0
处理结果
最后,经过这些操作,我们的特征变为了546维
损失与评估
这是一个回归模型,所以我采用了平方损失函数
$$
l=\frac{1}{2}(\hat{y}-y)^2
$$
但是我们思考,这个损失是否适合用来评估我们预测的结果?
思考一个极端的情况,一个1块的房子我预测了2块,和一个1000块的房子我预测了1001块,这两个数据的平方损失虽然是一样的,但是很明显后者的预测效果更好。
所以,评估房价,我们一般是看它的相对误差而不是绝对误差,也就是$\frac{\hat{y}-y}{y}$,把这个式子加上1,就是$\frac{\hat{y}}{y}$。我们把它取对数,就得到$\log{\hat{y}}-\log{y}$,对数相对于除法就好多了
最后整理成平方损失的形式再开方
$$
loss_{rmse}=\sqrt{(\log{\hat{y}}-\log{y})^2}
$$
这就是我们用来评估结果的函数,事实上kaggle官方就是用的这个函数进行评估。
看到这里,可能有人会有疑问,既然我们用log_rmse来评估损失,那为什么我们不拿它来做损失函数呢?
我们先来看看这两个函数的图像(这里就直接假设$label=1$)
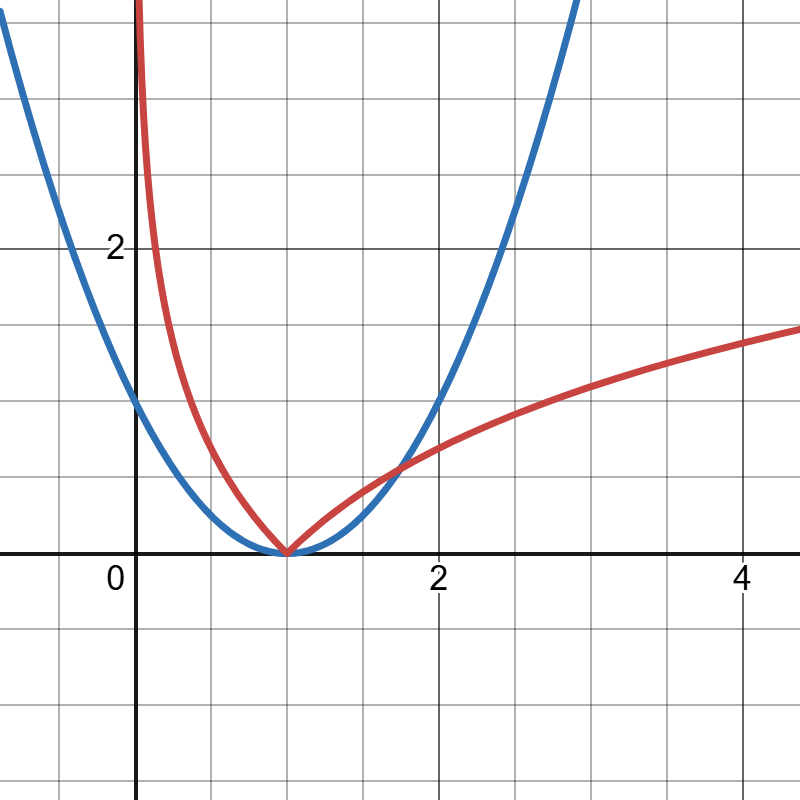
可以看到,对数损失在$x=1$时的梯度不为0,这很容易导致震荡,而且基本上预测值差距越大就梯度越小,根本就没法拿来做损失函数。
下面是对数损失的代码,注意要把预测值clamp一下,不能让它有负数
def log_rmse(y_hat, labels):
loss = nn.MSELoss()
clipped_preds = y_hat.clamp( min=1e-1 ,max=float('inf'))
labels = labels.clamp(min=1e-1, max=float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
return rmse然后我自己写了一个evaluator
class Evaluator:
def __init__(self, net, loss):
self.net = net
self.loss = loss
def evaluate_loss(self, data_iter):
if isinstance(self.net, nn.Module):
self.net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
y_hat = self.net(X)
l = self.loss(y_hat, y).mean()
metric.add(l , 1)
if isinstance(self.net, nn.Module):
self.net.train()
return metric[0] / metric[1]
def evaluate_loss_item(self, data_iter):
if isinstance(self.net, nn.Module):
self.net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
y_hat = self.net(X)
l = self.loss(y_hat, y).item()
metric.add(l , len(y))
if isinstance(self.net, nn.Module):
self.net.train()
return metric[0]Accumulator是我自己写的一个累加器
模型选择
我只会mlp就先用mlp~
net = nn.Sequential(
nn.Linear(num_input,n_hidden1),
nn.LeakyReLU(),
# nn.ReLU(),
nn.Dropout(p1),
nn.Linear(n_hidden1,n_hidden2),
nn.LeakyReLU(),
nn.Dropout(p2),
nn.Linear(n_hidden2,n_hidden3),
nn.LeakyReLU(),
nn.Dropout(p2),
nn.Linear(n_hidden3,n_hidden4),
nn.ReLU(),
nn.Dropout(p3),
nn.Linear(n_hidden4,num_output),
# nn.Dropout(p3),
# nn.Linear(n_hidden5,num_output),
).to(device)
net.apply(kaiming_init)
trainer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=lambd)模型是5层,激活函数主要用的leakyRelu,采用adam优化器,同时用权重衰减和dropout来正则化
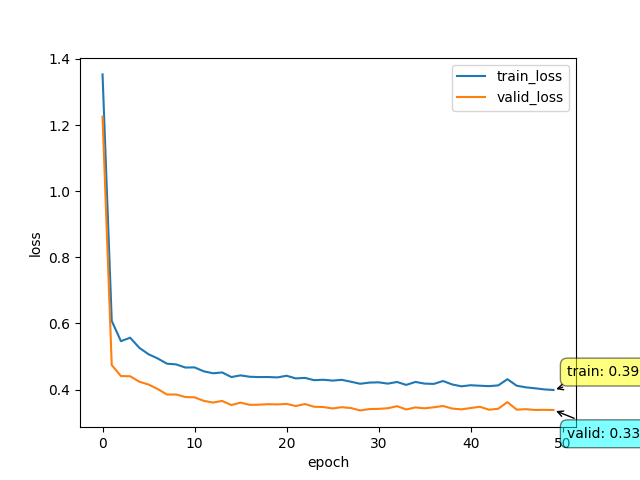
为什么要用leakyrelu呢?
我们前面提到,我们对数据进行了标准化,那么大概会有一半的数据输入是负的。如果使用relu,有可能会造成神经元坏死,梯度不更新。事实上实验的结果也是这样。
这是relu训练的结果
这是leakyrelu训练的结果
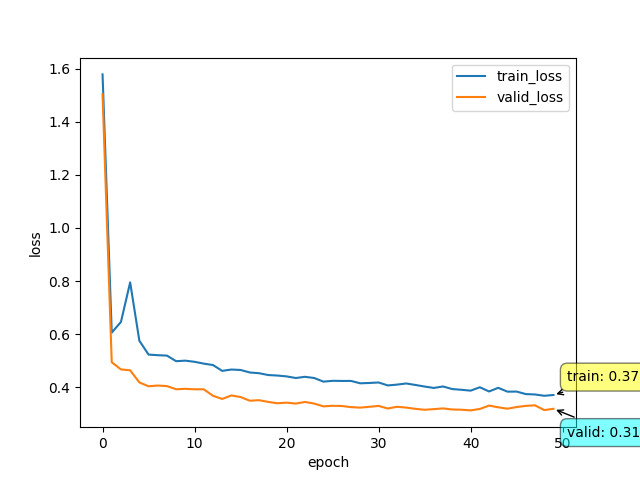
可以看到,leakyrelu提升了大约0.02的样子
训练
训练函数
def train_model(net,loss,num_epcoh,train_iter, valid_iter, trainer):
metric = Accumulator(3)
evaluator = Evaluator(net, log_rmse)
train_data=np.zeros(num_epcoh)
valid_data=np.zeros(num_epcoh)
if isinstance(net, nn.Module):
net.train()
for epoch in range(num_epcoh):
n = 0
print(f'epoch{epoch+1}')
for X,y in train_iter:
trainer.zero_grad()
n += 1
y_hat = net(X)
l = loss(y_hat,y)
log_l = log_rmse(y_hat, y)
valid_loss = evaluator.evaluate_loss(valid_iter)
l = torch.mean(l)
metric.add(log_l, valid_loss, 1)
train_data[epoch] += log_l
valid_data[epoch] += valid_loss
l.backward()
trainer.step()
train_data[epoch] /= n
valid_data[epoch] /= n
return metric, train_data, valid_data # 传出训练时的数据,训练和验证的损失训练时需要验证,但是又不舍得把训练集专门分出一部分来来做验证集,那我们就需要k折交叉验证
K折交叉验证
k折交叉验证的原理就是,把你的训练集分成k份,把你的模型跑k次,每次取其中一份来做验证集,其它的用来训练,最后合在一起再看看训练的效果
那么具体怎么在代码上实现呢?我的思路是写一个迭代器,迭代k次,每次传出这一折的训练集和验证集
class KfoldSubsetIter:
def __init__(self, k, dataset, batch_size=256, shuffle=True):
self.k = k
self.dataset = dataset # 传入数据集
self.data_num = len(dataset)
self.fold_num = self.data_num // k # 每折的样本数
self.batch_size = batch_size
self.indices = (torch.randperm(self.data_num) if shuffle else torch.arange(self.data_num,dtype=torch.long)).tolist() # 随机打乱索引
def __iter__(self):
for i in range(self.k):
start = i * self.fold_num
end = min(self.data_num, start+self.fold_num) # 防止越界
indices_train = self.indices[:start]+self.indices[end:] # 训练集索引
indices_valid = self.indices[start:end] # 验证集索引
train_subset = torch.utils.data.Subset(self.dataset, indices_train)
valid_subset = torch.utils.data.Subset(self.dataset, indices_valid)
train_subset = DataLoader(train_subset, batch_size=self.batch_size, shuffle=True, num_workers=get_num_workers())
valid_subset = DataLoader(valid_subset, batch_size=self.batch_size, shuffle=False, num_workers=get_num_workers())
yield train_subset, valid_subsetk折训练的函数
def k_fold_train(net, loss, num_epoch, dataset, trainer, k=5, batch_size=256):
k_fold_iter = KfoldSubsetIter(k, dataset, batch_size)
num_fold = 0
metric = Accumulator(2)
train_loss_data = np.zeros(num_epoch)
valid_loss_data = np.zeros(num_epoch)
for train_iter, valid_iter in k_fold_iter: # k折迭代
start = time.time()
# print(f'weight{net[0].weight[:1,:4]}') # type: ignore
net.apply(reset_parameters)
net.apply(kaiming_init)
if isinstance(net, nn.Module):
net.train()
print(f'Training Fold {num_fold+1}...')
# print(f'weight{net[0].weight[:1,:4]}') # type: ignore
num_fold += 1
fold_metric, train_data, valid_data = train_model(net, loss, num_epoch, train_iter, valid_iter, trainer)
train_loss = fold_metric[0] / fold_metric[2]
valid_loss = fold_metric[1] / fold_metric[2]
train_loss_data += train_data
valid_loss_data += valid_data
evaluator = Evaluator(net, log_rmse)
valid_loss = evaluator.evaluate_loss(valid_iter)
metric.add(train_loss, valid_loss)
end = time.time()
print(f'fold{num_fold},'f'Train Loss: {train_loss:.4f},' f'Validation Loss: {valid_loss:.4f},'f'Time: {end-start:.2f}s')
print(f'Average Train Loss: {metric[0] / k:.4f}')
print(f'Average Validation Loss: {metric[1] / k:.4f}')
train_loss_data = train_loss_data.astype(np.float32) / k
valid_loss_data = valid_loss_data.astype(np.float32) / k # 取平均
ploter = Ploter(train_loss_data, valid_loss_data)
# ploter.cpt_graph()
ploter.plot()
ploter.save("img/loss_curve.png")然后这些做完之后就是无休止的调参~
最后调出来
batch_size = 256
n_hidden1, n_hidden2, n_hidden3, n_hidden4, n_hidden5= int(num_input*1.5), int(num_input*1), num_input//2 , num_input//4, num_input//8
p1, p2, p3= 0.2, 0.25, 0.3
lr, lambd = 0.01, 0.0001尽力了
预测并提交
def train_and_pred(net, loss, num_epoch, train_dataset, test_dataset, trainer, batch_size=256):
train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_iter = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
if isinstance(net, nn.Module):
net.train()
print('Training...')
print(f'Epoch ')
for epoch in range(num_epoch):
print(f'{epoch}')
for X,y in train_iter:
trainer.zero_grad()
y_hat = net(X)
l = loss(y_hat,y)
l = torch.mean(l)
l.backward()
trainer.step()
if isinstance(net, nn.Module):
net.eval()
preds = []
print('Predicting...')
with torch.no_grad():
for X, _ in test_iter:
y_hat = net(X)
preds.append(y_hat.cpu().numpy())
submission = pd.read_csv('sample_submission.csv')
submission.iloc[:, 1] = np.concatenate(preds, axis=0)
submission.to_csv('submission.csv', index=False)存成一个csv交到kaggle官网上。
预测的结果有可能上下浮动,建议多提交几次。
代码
import time
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.nn.modules import Dropout, Linear
from torch.nn.modules.activation import ReLU
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import os
class Accumulator:
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def __getitem__(self, idx):
return self.data[idx]
def get_num_workers():
return 0
def load_data(train_path, test_path, device):
train_data = pd.read_csv(train_path)
test_data = pd.read_csv(test_path)
# train_data.info()
# test_data.info()
# print(train_data[:3])
# print(train_data[:3].to_string(max_colwidth=None))
#price存起来
train_label = train_data.iloc[:,2]
#
train_data = train_data.drop(train_data.columns[2], axis=1)
# train_data = train_data.drop(train_data.columns[0], axis=1)
num_train = train_data.shape[0]
# test_data = test_data.drop(test_data.columns[0], axis=1)
# print(train_data.iloc[:4,2])
data = pd.concat([train_data, test_data],ignore_index=True)
data = preprocess_data(data)
# print(train_data.shape)
# print(test_data.shape)
train_data = data.iloc[:num_train,:]
test_data = data.iloc[num_train:,:]
# print(train_data.shape)
# print(test_data.shape)
train_data = torch.tensor(train_data.to_numpy(), dtype=torch.float32).to(device)
train_label = torch.tensor(train_label.to_numpy(),dtype=torch.float32).to(device)
test_data = torch.tensor(test_data.to_numpy(), dtype=torch.float32).to(device)
train_label = train_label.view(-1,1)
train_dataset = TensorDataset(train_data,train_label)
blank_label = torch.zeros(test_data.shape[0],1)
test_dataset = TensorDataset(test_data,blank_label)
return train_dataset, test_dataset
def extract_top(features,data,sep,top_n=30):
for feature in features:
exploded = (
data[['Id', feature]]
.assign(**{feature: data[feature].str.split(sep)}) # 按sep分割
.explode(feature)
)
exploded[feature] = exploded[feature].str.strip() # 去除首尾空格
value_counts = exploded[feature].value_counts()
top_values = value_counts.head(top_n).index.tolist()
exploded[feature] = exploded[feature].apply(
lambda x: x if x in top_values else '0'
)
dummies = pd.get_dummies(exploded[feature], prefix=feature)
dummies['Id'] = exploded['Id']
dummies = dummies.groupby('Id',as_index=False).max()
dummies = dummies.drop('Id',axis=1)
data = data.drop(feature,axis=1)
data = pd.concat([data,dummies],axis=1)
return data
def precess_date(data, features):
for feature in features:
dates = pd.to_datetime(data[feature], errors='coerce')
data[f"{feature}_year"] = dates.dt.year.fillna(0).astype(int)
data[f"{feature}_month"] = dates.dt.month.fillna(0).astype(int)
data[f"{feature}_day"] = dates.dt.day.fillna(0).astype(int)
data = data.drop(feature, axis=1)
return data
def preprocess_data(data):
# 处理日期特征
date_features = ['Last Sold On','Listed On']
#data = data.drop(date_features, axis=1)
precess_date(data, date_features)
# 处理数值特征
numeric_features = data.select_dtypes(exclude=['object']).columns
numeric_features = numeric_features.drop('Id')
if len(numeric_features) > 0:
data[numeric_features] = data[numeric_features].apply(lambda x: (x-x.mean())/x.std())
data[numeric_features] = data[numeric_features].fillna(0)
# 处理分类特征
# data = data.drop('Summary', axis=1)
feature_listblank = ['Address']
data = extract_top(feature_listblank,data,' ')
feature_list = ['Summary','Heating', 'Cooling', 'Parking', 'Bedrooms', 'Flooring', 'Heating features','Cooling features','Appliances included','Laundry features','Parking features']
data = extract_top(feature_list,data,',')
categorical_features = data.select_dtypes(include=['object']).columns
if len(categorical_features) > 0:
# data[categorical_features] = pd.Categorical(data[categorical_features]).codes
# data = data.drop(categorical_features, axis=1)
data = extract_top(categorical_features,data,'',top_n=20)
data = data.fillna(0)
bool_features = data.select_dtypes(include=['bool']).columns
if len(bool_features) > 0:
data[bool_features] = data[bool_features].astype(int)
data = data.drop('Id', axis=1)
data = data.select_dtypes(include=['float64', 'int64'])
print(data.shape)
# print(data.dtypes)
# non_numeric_cols = data.select_dtypes(exclude=['float64', 'int64','bool']).columns
# print(non_numeric_cols)
return data
def kaiming_init(net):
for m in net.modules():
if isinstance(m,nn.Linear):
nn.init.kaiming_normal_(m.weight, nonlinearity='relu')
def reset_parameters(net):
for m in net.modules():
if isinstance(m, nn.Linear):
m.reset_parameters()
def log_rmse(y_hat, labels):
loss = nn.MSELoss()
clipped_preds = y_hat.clamp( min=1e-1 ,max=float('inf'))
labels = labels.clamp(min=1e-1, max=float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels)))
return rmse
def combine_loss(y_hat, y_label):
loss1 = torch.exp(log_rmse(y_hat, y_label))
# loss1 = log_rmse(y_hat, y_label)
mse_loss = nn.MSELoss()
loss2 = mse_loss(y_hat,y_label)
return loss1 + loss2
def train_model(net,loss,num_epcoh,train_iter, valid_iter, trainer):
metric = Accumulator(3)
evaluator = Evaluator(net, log_rmse)
train_data=np.zeros(num_epcoh)
valid_data=np.zeros(num_epcoh)
if isinstance(net, nn.Module):
net.train()
for epoch in range(num_epcoh):
n = 0
# print(f'epoch{epoch+1}')
for X,y in train_iter:
trainer.zero_grad()
n += 1
y_hat = net(X)
l = loss(y_hat,y)
log_l = log_rmse(y_hat, y)
valid_loss = evaluator.evaluate_loss(valid_iter)
l = torch.mean(l)
metric.add(log_l, valid_loss, 1)
train_data[epoch] += log_l
valid_data[epoch] += valid_loss
l.backward()
trainer.step()
train_data[epoch] /= n
valid_data[epoch] /= n
return metric, train_data, valid_data
class KfoldSubsetIter:
def __init__(self, k, dataset, batch_size=256, shuffle=True):
self.k = k
self.dataset = dataset # 传入数据集
self.data_num = len(dataset)
self.fold_num = self.data_num // k # 每折的样本数
self.batch_size = batch_size
self.indices = (torch.randperm(self.data_num) if shuffle else torch.arange(self.data_num,dtype=torch.long)).tolist() # 随机打乱索引
def __iter__(self):
for i in range(self.k):
start = i * self.fold_num
end = min(self.data_num, start+self.fold_num) # 防止越界
indices_train = self.indices[:start]+self.indices[end:] # 训练集索引
indices_valid = self.indices[start:end] # 验证集索引
train_subset = torch.utils.data.Subset(self.dataset, indices_train)
valid_subset = torch.utils.data.Subset(self.dataset, indices_valid)
train_subset = DataLoader(train_subset, batch_size=self.batch_size, shuffle=True, num_workers=get_num_workers())
valid_subset = DataLoader(valid_subset, batch_size=self.batch_size, shuffle=False, num_workers=get_num_workers())
yield train_subset, valid_subset
class Ploter:
def __init__(self,train_loss, valid_loss):
self.train_loss = train_loss
self.valid_loss = valid_loss
def cpt_graph(self):
plt.plot(self.train_loss, label='train_loss')
plt.plot(self.valid_loss, label='valid_loss')
plt.xlabel('epoch')
plt.ylabel('loss')
self._add_last_point_annotation()
plt.legend()
def plot(self):
plt.plot(self.train_loss, label='train_loss')
plt.plot(self.valid_loss, label='valid_loss')
plt.xlabel('epoch')
plt.ylabel('loss')
self._add_last_point_annotation()
plt.legend()
plt.show()
def _add_last_point_annotation(self):
# 获取最后一个点的坐标
last_epoch = len(self.train_loss) - 1
last_train = self.train_loss[-1]
last_valid = self.valid_loss[-1]
# 添加训练损失标注
plt.annotate(f'train: {last_train:.4f}',
xy=(last_epoch, last_train),
xytext=(10, 10), textcoords='offset points',
bbox=dict(boxstyle='round,pad=0.5', fc='yellow', alpha=0.5),
arrowprops=dict(arrowstyle='->'))
# 添加验证损失标注
plt.annotate(f'valid: {last_valid:.4f}',
xy=(last_epoch, last_valid),
xytext=(10, -20), textcoords='offset points',
bbox=dict(boxstyle='round,pad=0.5', fc='cyan', alpha=0.5),
arrowprops=dict(arrowstyle='->'))
def save(self, filename="loss_curve.png"):
self.cpt_graph()
# 如果文件已存在,生成新文件名
if os.path.exists(filename):
base, ext = os.path.splitext(filename)
counter = 1
while os.path.exists(f"{base}_{counter}{ext}"):
counter += 1
filename = f"{base}_{counter}{ext}"
plt.savefig(filename)
plt.close()
print(f"图像已保存为: {filename}")
def k_fold_train(net, loss, num_epoch, dataset, trainer, k=5, batch_size=256):
k_fold_iter = KfoldSubsetIter(k, dataset, batch_size)
num_fold = 0
metric = Accumulator(2)
train_loss_data = np.zeros(num_epoch)
valid_loss_data = np.zeros(num_epoch)
for train_iter, valid_iter in k_fold_iter: # k折迭代
start = time.time()
# print(f'weight{net[0].weight[:1,:4]}') # type: ignore
net.apply(reset_parameters)
net.apply(kaiming_init)
if isinstance(net, nn.Module):
net.train()
print(f'Training Fold {num_fold+1}...')
# print(f'weight{net[0].weight[:1,:4]}') # type: ignore
num_fold += 1
fold_metric, train_data, valid_data = train_model(net, loss, num_epoch, train_iter, valid_iter, trainer)
train_loss = fold_metric[0] / fold_metric[2]
valid_loss = fold_metric[1] / fold_metric[2]
train_loss_data += train_data
valid_loss_data += valid_data
evaluator = Evaluator(net, log_rmse)
valid_loss = evaluator.evaluate_loss(valid_iter)
metric.add(train_loss, valid_loss)
end = time.time()
print(f'fold{num_fold},'f'Train Loss: {train_loss:.4f},' f'Validation Loss: {valid_loss:.4f},'f'Time: {end-start:.2f}s')
print(f'Average Train Loss: {metric[0] / k:.4f}')
print(f'Average Validation Loss: {metric[1] / k:.4f}')
train_loss_data = train_loss_data.astype(np.float32) / k
valid_loss_data = valid_loss_data.astype(np.float32) / k # 取平均
ploter = Ploter(train_loss_data, valid_loss_data)
# ploter.cpt_graph()
ploter.plot()
ploter.save("img/loss_curve.png")
class Evaluator:
def __init__(self, net, loss):
self.net = net
self.loss = loss
def evaluate_loss(self, data_iter):
if isinstance(self.net, nn.Module):
self.net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
y_hat = self.net(X)
l = self.loss(y_hat, y).mean()
metric.add(l , 1)
if isinstance(self.net, nn.Module):
self.net.train()
return metric[0] / metric[1]
def evaluate_loss_item(self, data_iter):
if isinstance(self.net, nn.Module):
self.net.eval()
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
y_hat = self.net(X)
l = self.loss(y_hat, y).item()
metric.add(l , len(y))
if isinstance(self.net, nn.Module):
self.net.train()
return metric[0]
def train_and_pred(net, loss, num_epoch, train_dataset, test_dataset, trainer, batch_size=256):
train_iter = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_iter = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
if isinstance(net, nn.Module):
net.train()
print('Training...')
print(f'Epoch ')
for epoch in range(num_epoch):
print(f'{epoch}')
for X,y in train_iter:
trainer.zero_grad()
y_hat = net(X)
l = loss(y_hat,y)
l = torch.mean(l)
l.backward()
trainer.step()
if isinstance(net, nn.Module):
net.eval()
preds = []
print('Predicting...')
with torch.no_grad():
for X, _ in test_iter:
y_hat = net(X)
preds.append(y_hat.cpu().numpy())
submission = pd.read_csv('sample_submission.csv')
submission.iloc[:, 1] = np.concatenate(preds, axis=0)
submission.to_csv('submission.csv', index=False)
if __name__ =='__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = 'cpu'
print(f"Using device: {device}")
train_path = 'train.csv'
test_path = 'test.csv'
batch_size = 256
train_dataset, test_dataset = load_data(train_path, test_path, device)
print("load complete")
# print("train_iter length:", len(train_iter))
num_input, num_output= train_dataset.tensors[0].shape[1], 1
# print("num_input:", num_input)
n_hidden1, n_hidden2, n_hidden3, n_hidden4, n_hidden5= int(num_input*1.5), int(num_input*1), num_input//2 , num_input//4, num_input//8
p1, p2, p3= 0.2, 0.25, 0.3
lr, lambd = 0.01, 0.0001
# loss = log_rmse
loss = nn.MSELoss()
#loss = combine_loss
num_epoch = 50
net = nn.Sequential(
nn.Linear(num_input,n_hidden1),
nn.LeakyReLU(),
# nn.ReLU(),
nn.Dropout(p1),
nn.Linear(n_hidden1,n_hidden2),
nn.LeakyReLU(),
nn.Dropout(p2),
nn.Linear(n_hidden2,n_hidden3),
nn.LeakyReLU(),
nn.Dropout(p2),
nn.Linear(n_hidden3,n_hidden4),
nn.ReLU(),
nn.Dropout(p3),
nn.Linear(n_hidden4,num_output),
# nn.Dropout(p3),
# nn.Linear(n_hidden5,num_output),
).to(device)
net.apply(kaiming_init)
trainer = torch.optim.Adam(net.parameters(), lr=lr, weight_decay=lambd)
k_fold_train(net, loss, num_epoch, train_dataset, trainer, k=5, batch_size=batch_size)
# train_and_pred(net, loss, num_epoch, train_dataset, test_dataset, trainer)总结
数据处理很重要,特征工程做好能有很大提升
Comments NOTHING